
5 Oct 2021 by David Mountain
Data quality is fundamental to everything we do at TransportAPI. We ingest data sources from across the industry and have learned the signs of what good and poor quality data looks like. We mitigate for issues as much as we are able, but fundamentally, improvement is driven by reporting specific problems back to data source providers, and explaining how they should be resolved. Things rarely get better by themselves: knowing how good something is, and then seeing how this changes over time, is key. Things that are measured, tend to improve.
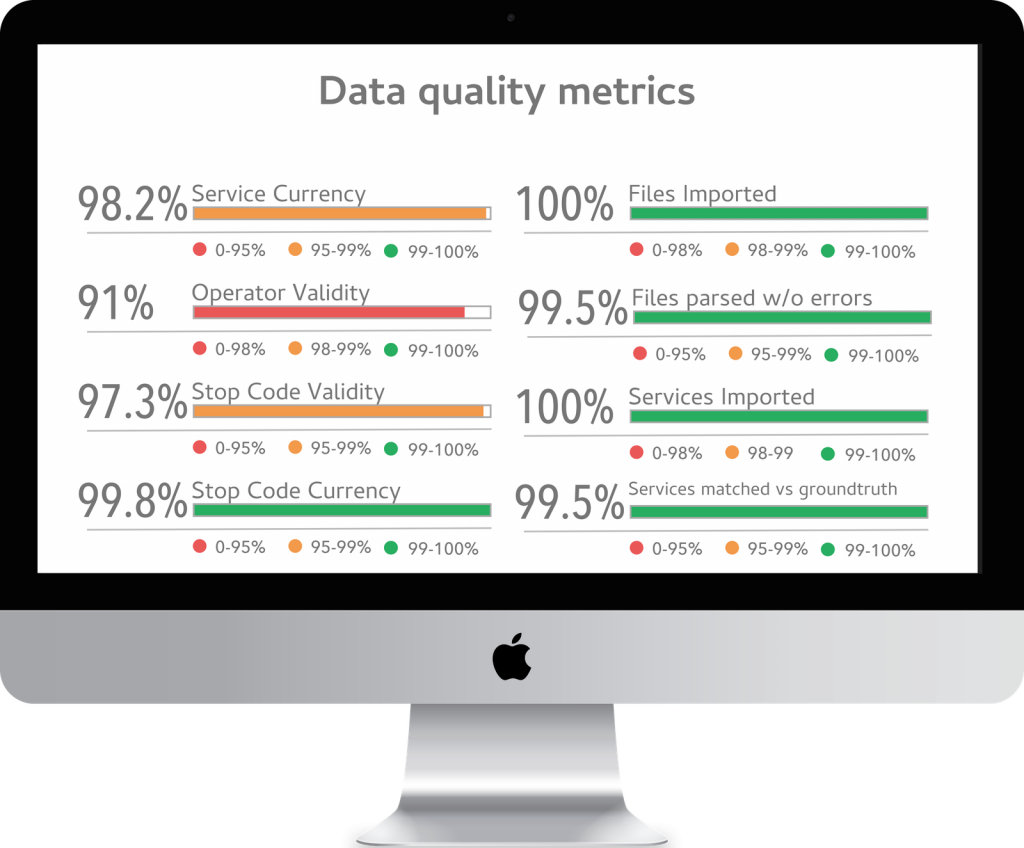
A big part of the problem with data quality is that whilst everyone knows bad data when they see it, it is very hard to define. Saying that your data is 99.9% correct isn’t much help, if no-one agrees what correct looks like.
To help us better define all the different aspects of data quality, we adopted ISO standard 19157:2013 Geographic Information — Data Quality that breaks the big mess of data quality problems into distinct dimensions.
There are five of these dimensions at the top level:
- completeness: are things (or attributes of things) that are expected to be present, missing? E.g. service 185 should be in the schedules, but isn’t;
- attribute accuracy: are attribute values incorrect? E.g. a bus journey has the direction ‘inbound’, when it should be ‘outbound’;
- spatial accuracy: are things in the right place? E.g. a bus stop in our dataset is 10 metres away from its location in real life;
- temporal quality: are time values incorrect (e.g. in real life a bus calls at a stop at 13:00, not 12:55 as stated in the schedules), or has the data gone stale;
- consistency: is the format of the data correct, or are there logical consistency issues, such as a bus calling at the last stop before the first one.
We use this framework to define metrics, and compare their values to thresholds set to identify problematic data. If any one transport operator is missing from a dataset, this could be a big problem. By defining a Missing Operator metric, with a threshold of 0%, we can account for this scenario. For stale data we might choose to be more forgiving: with bus schedules there is often some data in the past. For example school services only run in term time, but often still linger in the dataset into the start of the Summer holidays. A Service Currency metric – with threshold set to 98% – can allow us to account for this baseline, whilst catching more issues such as an entire operator submitting stale data.
We use these metrics everywhere: in our data quality reporting, every time we load new data; for continuous monitoring of realtime systems; for automated alerts that ping us if metrics are falling below their thresholds.
And what good does all this do? What’s in it for you?
Well, of the 15,000 or so bus services in GB, we routinely catch those that are out of date (because, for example, an operator submitted last week’s schedules instead of this week’s), and report this back. This maintains up to date information on the apps and websites that use our managed services for bus stop departures, bus journey information, and journey planning, and avoids missing or legacy schedules being seen.
Equally, for the half a million bus stops in the UK, we can flag problems, such as when schedulers use unrecognised or legacy bus stop codes, or failed to include spatial information, which prevents stops being plotted on a map. We mitigate such issues where we can, but we also report a targeted list of what needs to be done for the data provider, to correct these problems at source and avoid them happening again in future.
Above are just two examples that show how we maintain data quality in our TAPI Places, TAPI Bus Schedules, and TAPI Bus RTI managed services. But we have hundreds more, monitoring all dimension of data quality across managed services. It gives us the evidence not only to believe that we are serving you the most complete and accurate industry data, but also to ensure that it continues to improve.