
6 Feb 2024 by Jonathan Raper
Your customers made a rail journey and it was late. Or it was early… or diverted. Or it may have been cancelled or even removed from the timetable. You might have had problems with your reservations… or there was no wifi. Or a particular service is overcrowded for part of the journey each day. A customer service enquiry might be about a missed connection because a train run by a different operator was late. Or maybe they all just ran beautifully and you would like to share…
But how can you refer to that train or that journey without resorting to ‘it was the 18:44 from Stockport to London Euston last Tuesday’?
The good news is that there are at least four different ways of referencing a rail journey describing all the different issues mentioned above. However, that is also the bad news, because each of those systems was designed to describe something different and they overlap in a variety of different ways. TransportAPI has been working to bring these rail referencing systems together so you can look up trains by any of the four systems and find the other references. Armed with those references you can connect up all the information about rail journeys from delay-repay to reservations to wifi, so here is a quick summary of the four systems.
Let’s take a particular train, say the London Victoria (VIC) to Horsham (HRH) scheduled to arrive at 11.02 on 1st February 2024. The graphic shows the 4 different ways we can refer to this train:

-
The TRAIN_UID (top right, red) has a letter and 5 numbers, which relates to the train’s position in the set of trains in the timetable
-
The RETAIL SERVICES ID (RSID) (bottom, green) has two letters for the train operator (in this case Southern), 4 identifying digits and then two digits at the end that are zero unless the train splits during the journey
-
The HEADCODE (left, pink) has a single digit that is 1, 2 or 9 (to denote a passenger train that is in service), a letter that indicates the route the train follows, and then two digits that indicate the number of the train in the sequence of services passing over that route in that day.
-
The Darwin RID (top left, light blue), which consists of the YYYYMMDD formatted date plus the TRAIN_UID (the letter in TRAIN_UID is converted to the two digit number in ASCII code)
These four systems exists because the different organisations running the railway each use different systems to refer to trains. Hence:
-
Network Rail manages the timetabling process generating a unique TRAIN_UID for each scheduled train service and a HEADCODE to be a short form train reference to describe each ‘run’ of a service over a route with a particular stopping pattern (normally odd and even numbers for the different directions);
-
Train operators produce the RSID to allow them to link to reservations and to refer to each portion of a train, so that if a train splits then they can add a suffix number to uniquely identify it;
-
National Rail Darwin system assigns a distinct RID to each separate run of a service on each day by adding the date to the TRAIN_UID… and this is the only reference that uniquely identifies the London Victoria (VIC) to Horsham (HRH) scheduled to arrive at 11.02 on 1st February 2024
If you put these references together across a service pattern you get a picture of how trains can be differentiated from each other. In the graphic below we see all three southbound arriving services at Horsham on 1st February 2024 between 11am and noon:
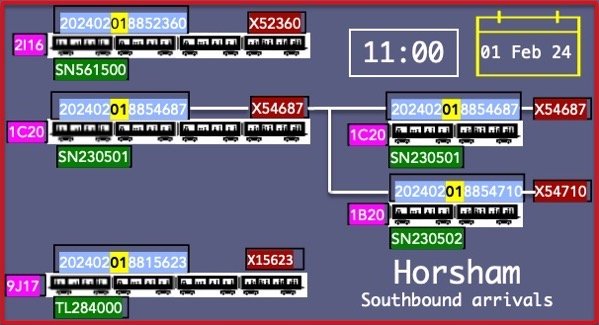
The three arrivals are:
-
2I16 from London Victoria (VIC) that terminates a Horsham (HRH) consisting of a single train portion
-
9J17 from Peterborough (PBO) that terminates a Horsham (HRH) consisting of a single train portion
-
1C20 from London Victoria (VIC) that splits at Horsham (HRH) into two portions
The front portion of the 1C20 goes forward to Portsmouth & Southsea (PMS) and retains the TRAIN_UID, HEADCODE and RID identity of the train that originally departed from London Victoria. However, it has lost half it’s carriages and the only way to link the two portions is to look at the last digits of the RSID, which show that this is portion 01. The other portion goes to Bognor Regis with a different stopping pattern and so it has a new TRAIN_UID, RID and HEADCODE. However, it has the same RSID as the original service from London Victoria to Horsham, but with a 02 to indicate that it is portion 2 of the original service.
If a customer moved between the portions while 1C20 was a single train, but left a bag on the other portion then this is the easiest way to link the portions to find the lost property and the portion they travelled on as they both have the same RSID (SN2305nn). If any of these services ran late or were cancelled you need the RID as this describes the specific run of the service on a particular day for which customers might claim delay-repay compensation. The HEADCODE is largely used by staff for rostering and train consist as it is a short and memorable reference to the service that will be run each day at that time to the same destination.
Meanwhile, the TRAIN-UID is largely important to schedulers as it is only important for timetables. The TRAIN_UID repeats on each day of the same timetable at the same times… but it does change if there is a disruption, strike or new timetable. It is quite a lot more difficult to remember than a HEADCODE. See how these references change within a day and between days:
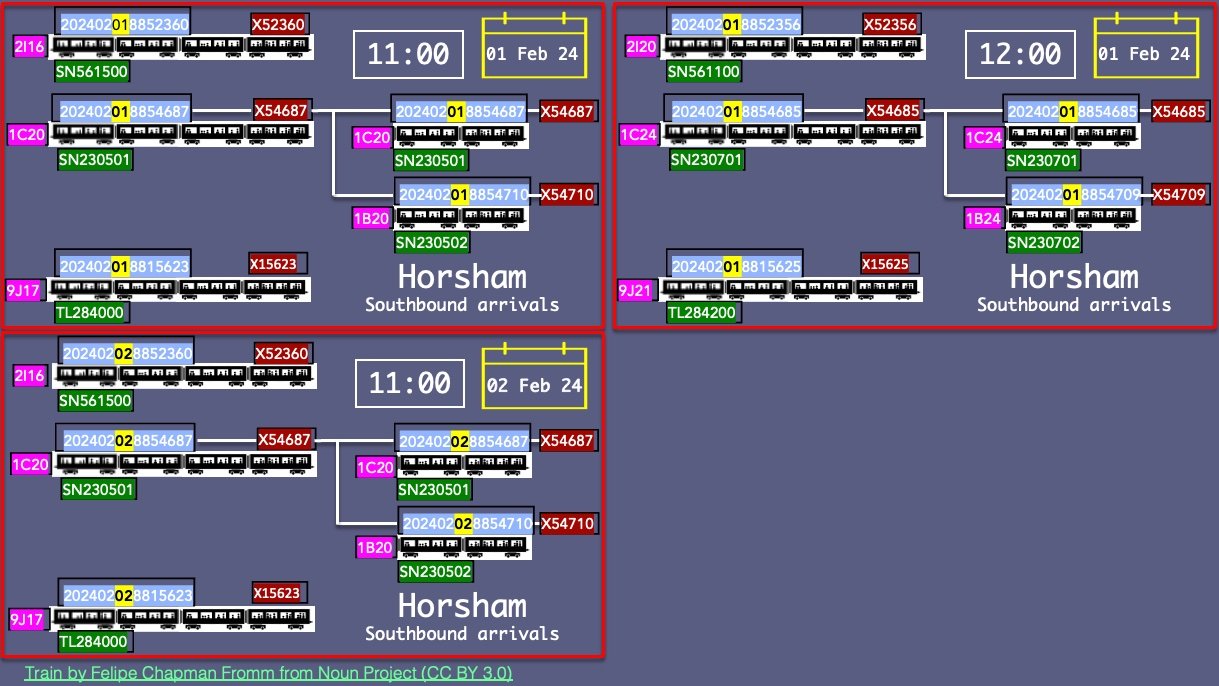
Historically, these four systems have been archived in different places, and it has not been easy to search the archives by any of these references and automatically find the others. For example, National Rail RTTI Historic does not have the RID and the Historic Performance Service does not However, working with Northern Rail, TransportAPI has brought all these references together in the TAPI Rail Performance managed service… as shown in the Rail Performance Explorer web version below. Clicking the tab at the left opens up on the display of the state of the journey at any chosen point.
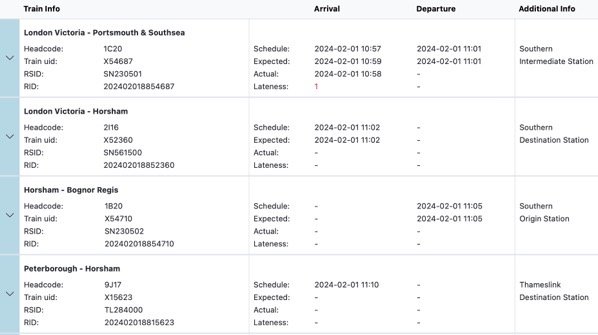
TAPI Rail Performance managed service can be accessed by API so that web applications, apps and screens can be programmed to run repeated queries or business systems like Salesforce can be designed to pull in the full journey history if there is a customer enquiry. All the historic data is in one place labelled with all 4 references so you don’t have to switch between systems, which is especially useful when the customer is on the line.
Understanding rail referencing systems matters because that is the way to link all aspects of performance together. Consistently below average satisfaction scores in customer surveys can be linked to a variety of different delivery systems each using its own referencing … but without a link between these referencing systems, the causes of performance issues will be harder to find.